Service Mesh 101: Everything You Need to Know

When building software, code can be structured as a single large program (monolith) or multiple smaller programs (microservices). While it is true that many organizations are migrating from monolith to microservices to leverage the flexibility and scalability microservices offer, it gets difficult to manage them as their number grows. Challenges arise in tracking, latency control, optimizing load between replicas of a service, service-to-service communication security, and maintaining resilience. All these features can be encoded with the service giving an opportunity for vulnerabilities & mixing of business logic with management logic.
Implementing a reliable service discovery mechanism and maintaining an up-to-date service registry becomes difficult. Adopting Kubernetes resolves some deployment issues, but runtime issues persist due to tight coupling with the application. Testing new features and making changes while maintaining infrastructure security becomes challenging.
Service mesh fills this gap and helps build a secure infrastructure with the optimized usage of the service by adding reliability, observability, and security features across all services uniformly without any application code change. In this blog post, we will understand the concept of the service mesh, its components, its functionality, and how it can be helpful in Kubernetes and beyond.
What is a service mesh?
Service mesh is an infrastructure layer deployed alongside an application, which means all the network complexities are handled outside the application code. It operates independently from the application and provides capabilities to optimize networking and enable service-to-service communication. By configuring and managing network behavior and traffic flow through policies, the service mesh enhances the application’s networking capabilities.
Why is a service mesh needed?
There are multiple reasons why an organization would wish to implement a service mesh. We can start with the API endpoint discovery feature of service mesh that helps in identifying the backend service based on the client’s request and preventing the exposure of the API to unauthorized access. Another reason is that an outbound proxy can only protect the cluster or VMs from the outside. However, once a request enters the infrastructure, all communication becomes insecure, and the request gains access to all the services. This leaves it vulnerable to potential threats.
Service mesh fills this gap and routes all the inter-service communication through proxies. It allows platform engineers to rate limit, trace, access control, etc. the service request which helps in keeping the infrastructure secure. Though very frequently used with Kubernetes and microservices, service mesh can be used outside of microservices and containers on virtual or bare metal servers. Let us understand the architecture of service mesh to know how we can modernize existing services.
Service mesh architecture
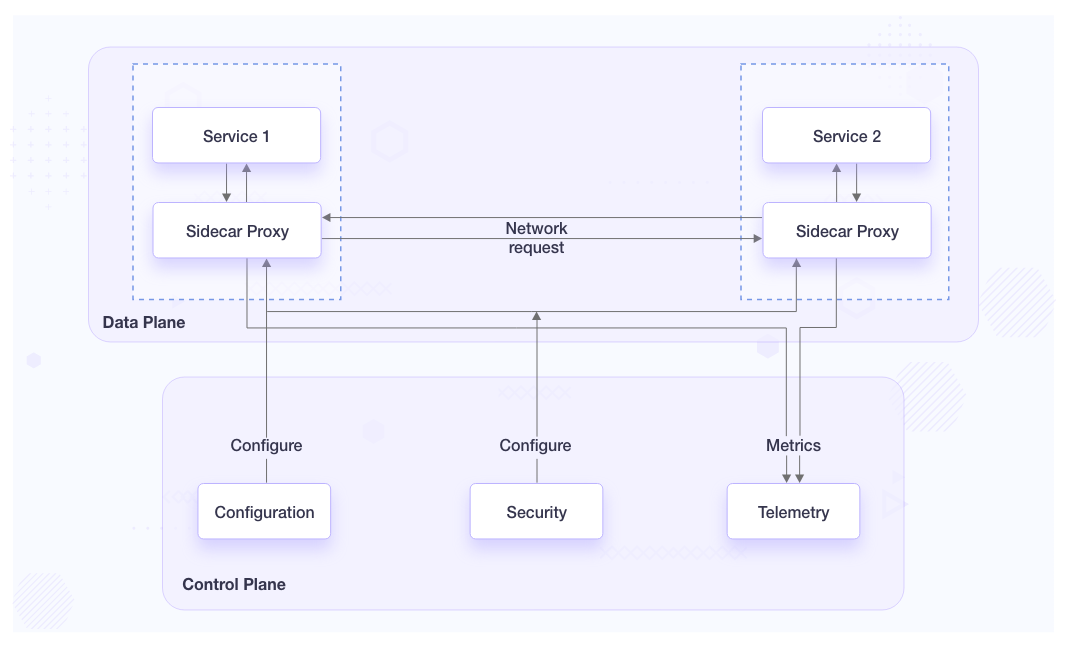
Service mesh is designed on the basis of the Software Defined Network (SDN) architecture. It has two major components, i.e. control plane and the data plane. With one or more control planes that act as the brain of the service mesh, multiple data planes can be configured to process the traffic flow using the policy specified by the control plane.
Let’s understand each of these components in detail.
Control plane
A control plane establishes and enforces the policy in a service mesh. It controls the requests that will flow inside the service mesh by having up-to-date configuration information about all the components in the service mesh. Without a control plane, the API request would fail to understand how to take the request to the destination. Along with that, the service needs to know which request it could accept or reject.
Platform engineers interact with the control plane using the CLI or API. The control plane provides the configuration of the data plane. It supervises the complete configured network by collecting metrics from the data plane via network calls.
Data plane
The data plane handles the network traffic between services. Usually, it consists of proxies deployed alongside the service. For the same reason, they are also called sidecars and are completely decoupled from the application’s code. It exists in the same network in which the service exists and for each communication happening to and from the service. In the case of containerized architecture, they should be in the same pod.
Such schema allows the application to be more flexible and resilient. A proxy can be independently upgraded without recompiling or redeploying the application. A service can be rate-limited, traced, load balanced, authenticated, etc. with the help of a proxy. Continuous metrics are being fetched and sent to the control plane to observe the behavior of the service like the number of requests incoming or outgoing per second, the health status of each service, concurrent requests, routing, etc.
Though sidecars have been in the picture since the service mesh emerged, they can be replaced with a secure overlay that runs a daemon on each service node in an ambient mesh. It helps reduce operational costs and provides all the functionalities of service mesh. Its implementation may require a little deeper understanding of the required use case. Similarly, there are service meshes that are sidecarless like Cilium. At the foundation, it has eBPF based data plane and provides networking, observability, and security solution.
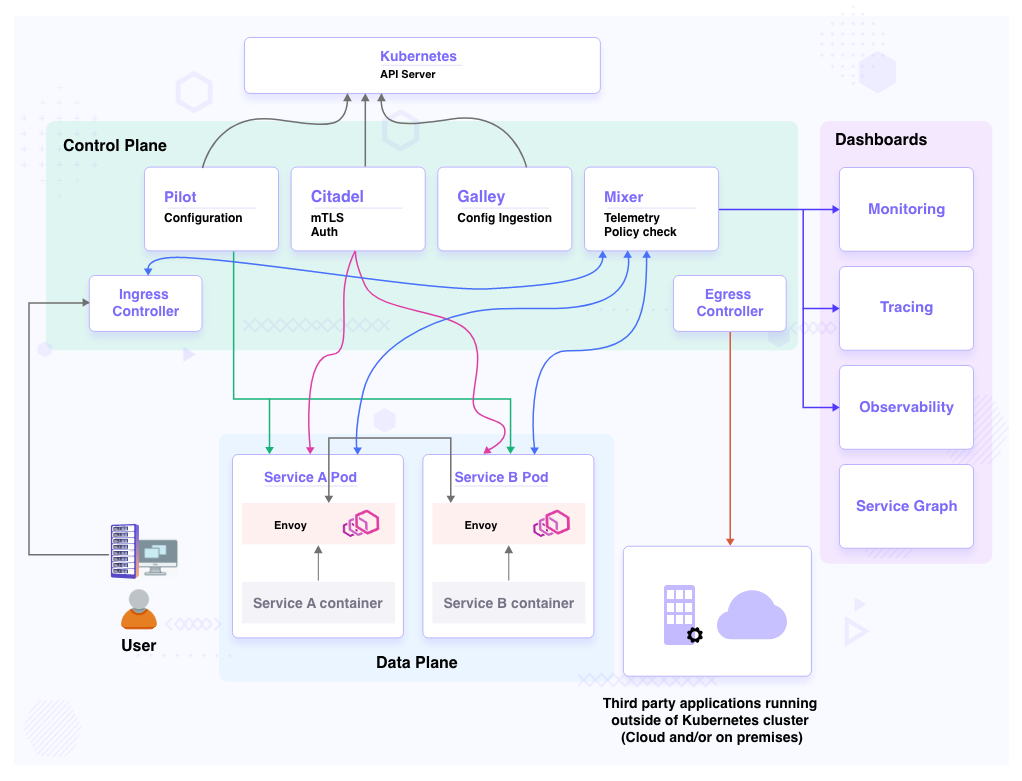
Following is the representation of a typical service mesh implemented by Istio. It uses Envoy as the sidecar (proxy) for the data plane and provides monitoring, tracing, and observability over services via dashboards.
How does service mesh work?
A service mesh works using the data plane and the control plane. The data plane manages all the inbound and outbound traffic on behalf of the service and the control plane manages the data planes.
Let us suppose there are 100s of services that make an application like an e-commerce platform. Such applications may not necessarily have all the services running geographically near each other. In such cases, the network complexities like handling latency, ensuring secure communication, authorization, etc. could be challenging to manage or monitor if tightly coupled with the application.
Service mesh abstracts these network complexities via proxy. So when a service has to communicate with another service, the service mesh exactly knows how to do it. Let us understand it’s working in a real-world scenario.
Understanding service mesh working with real-world scenarios
Real-time problem
An organization has a large-scale e-commerce platform that consists of multiple interconnected services responsible for various tasks such as user authentication, product catalog management, inventory management, payment processing, and order fulfillment. One common problem in such a distributed system is ensuring that the network is secure so that the communication across these services is reliable.
Kubernetes provides a basic level of security with network policies but does not enforce any security over the internal cluster communications. Such organizations face issues causing outages that have significant downtime costs.
Solution without a service mesh
In such a case, implementing security or encryption with the service would require updating business logic. This would also mean that the development team would spend more time on ensuring security rather than other priorities.
Solution with service mesh
With a service mesh, the business logic does not need to be changed. The platform team can apply mutual TLS encryption to all the traffic within the system. Some of the other benefits that service mesh gives include:
- The service that is requesting let’s say product catalog, can directly query without scanning all services.
- Before initiating the exchange of information, the services ensure that the source of the request is reliable and authorized.
- The communication is encrypted so there are minimal chances of eavesdropping or man-in-the-middle attacks.
What are service mesh use cases?
The data plane of a service mesh provides the flexibility to upgrade the network components without playing around with the application’s code. Some of the use cases that add to this flexibility include the following which will help you understand why you need a service mesh.
Service discovery
The control plane maintains the central registry of all the available services in the mesh and their address. For any inter-service communication, sidecar queries this registry and it returns the list of the right services with which communication can be done. Service discovery also helps announce in the mesh that a new replica of the service has been deployed. This makes it easier for platform engineers to scale the application without writing their own services infrastructure code.
Deployment strategies
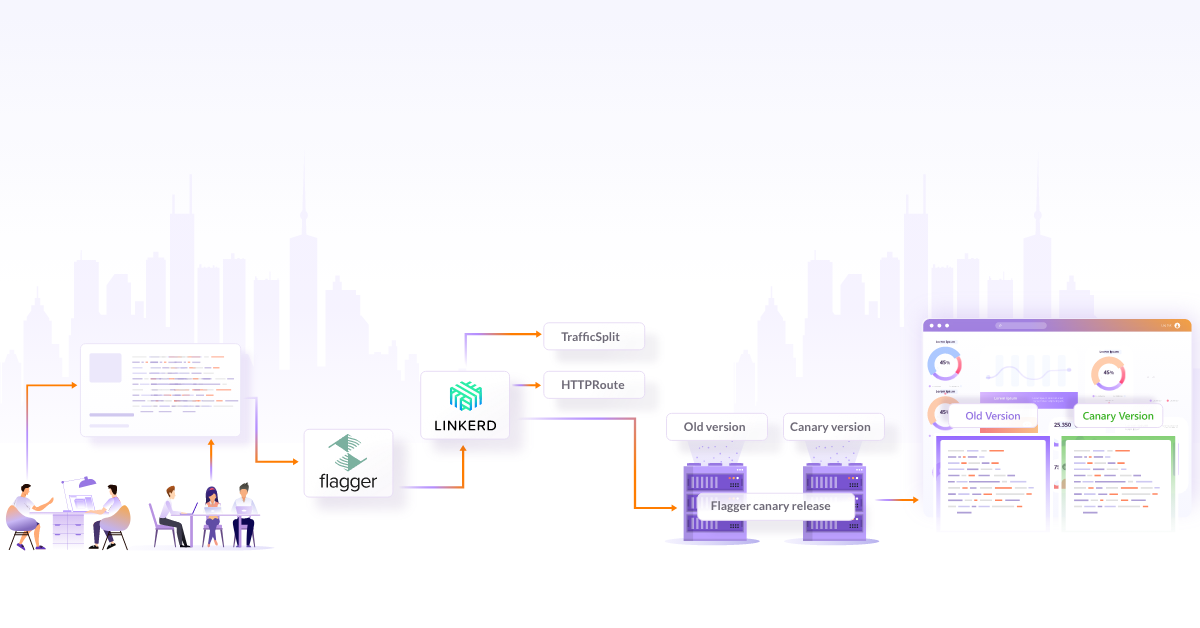
Service mesh also helps with deployment rollouts like canary and blue-green deployments. It gives better control of canary deployments by routing a small percentage of traffic to a new version of the service based on criteria like region, the user, or other properties of the request.
Let’s suppose you set to route 1% of traffic for the Canary version. For this, you do not need to spin up many replicas of the service. The data plane can be configured to route traffic to the specific service proxy. If there is any issue observed, it can easily roll back. With Kubernetes, it is only possible to do this on the basis of the replica ratio.
For a better-tested new version of the application, service mesh makes it possible to do blue-green deployments with much ease. Without disrupting the live application, developers can leverage feature flags to control feature access in a blue-green deployment. This could help with launching features fast and easy feature rollback in case anything goes wrong. Using weight-based routing, traffic can be shifted to a newer version of the service to allow stuff like A/B testing.
Security
In a service mesh, communication happens via peers, via a request, etc. which can be secured by enabling security. Some of the methods include:
-
Identity management: To determine the identity of the request’s origin, service mesh provides identity management functionality. The Control Plane can be configured to have a Certificate Authority (CA) which signs the certificate and sends it to the sidecar. It monitors the certificate expiration and periodically rotates the key and certificate. This makes it easier to control the traffic and allows only authorized access to the services. It helps avoid issues like Denial of Services (DOS) or service unresponsive due to flooding of unauthorized requests. A service mesh like Linkerd, Istio, etc. provides the feature to enable authorization policy.
-
Mutual TLS authentication: When a request makes it into the cluster or VMs, it has access to all the services which could lead to unauthorized access to services. It can initiate requests from one service to another leading to threats. To secure service-to-service communication, service mesh tunnels it through the client-side and server-side Policy Enforcement Points (PEPs) which are available in the data plane. The client-side proxy and the server-side proxy establish a mutual TLS connection after the successful mutual TLS handshake. This helps in identifying any unauthorized initiation of a request and rejecting it. Since the communication is encrypted, it helps avoid eavesdropping and man-in-the-middle attacks. Read more about how mTLS works in Istio.You can also prevent unauthorized access by implementing request level authentication and authorization using Istio & Keycloak.
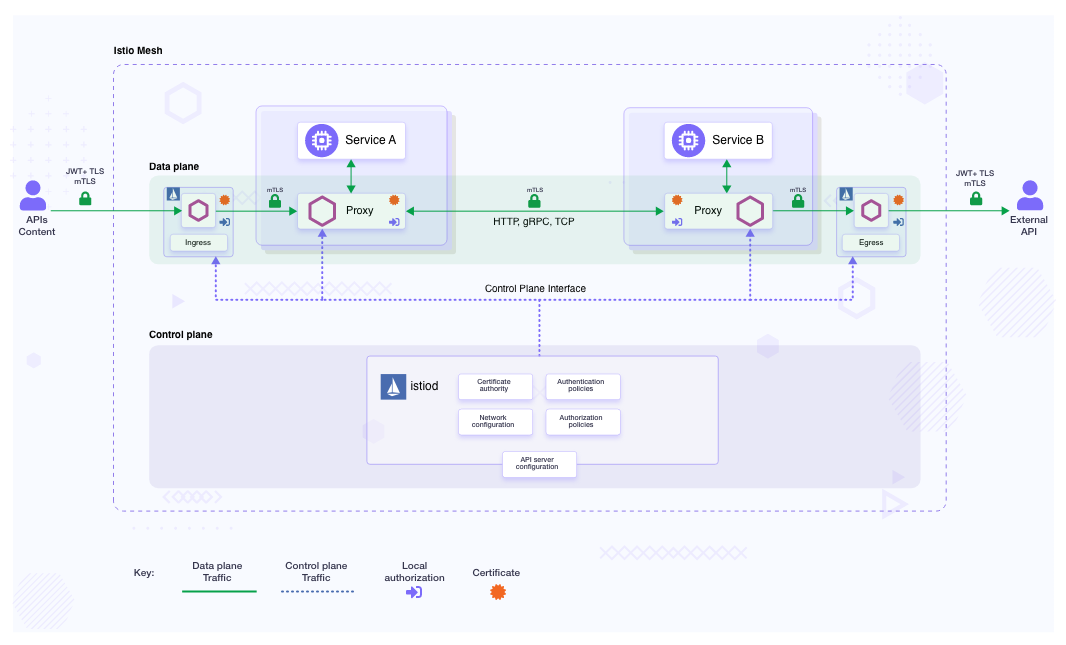
Following is a high-level overview of the security architecture implemented in the Istio service mesh
Traffic control
A service mesh’s basic functionality includes service discovery and load balancing. Most applications have multiple instances of each service to handle the workload traffic. To distribute traffic across these instances, the service mesh’s data plane can be configured using some supported models like round-robin, random, weighted least request, etc. for routing traffic to a healthy service. If a health check is not implemented, all the services are considered healthy and then the request is routed based on the model used.
Gateway in a service mesh is used to manage the mesh’s inbound and outbound traffic. These configurations are applied to proxies running at the edge of the mesh rather than the service sidecar proxy. It can be used to configure load-balancing properties like ports to expose, TLS settings, etc.
Along with routing the traffic, service mesh also provides the ability to handle runtime issues or failure recovery options such as the following.
Circuit breaker
Each host for a service has a limit or condition defined such as the maximum number of concurrent connections, the number of 5xx errors, the maximum number of pending requests, the maximum number of retries, etc. Once any of these thresholds is reached, the circuit breaker stops further connections to that host by marking it unhealthy. This makes sure that no additional traffic can reach an unhealthy data plane proxy until it is healthy again.
Fault injection
With fault injection, errors can be introduced in the system to check its resiliency and failure recovery capacity. Basic fault injection techniques allow injecting errors at the network layer such as delaying packets. Service mesh also allows injecting more relevant failures at the application layer such as HTTP error codes.
Retries
With retry, the maximum number of times a proxy attempts to connect to a service if the initial call fails can be defined in a set of intervals. This helps to ensure that a request does not permanently fail because of temporary issues like overloaded service or network. A caution, in this case, is that the value has to be set in a way that does not impact the application needs like availability and latency.
Timeouts
A limit is set on the proxy for the amount of time it has to wait for a response from the service once a request has been initiated. This ensures that the call succeeds or fails in a predetermined time. For a too-long timeout, latency may get impacted. For a too-short one, the request may fail unnecessarily so service mesh allows to adjust timeouts dynamically on-per service basis.
Observability
The control plane collects the telemetry from all the data planes in the mesh to provide observability of service behavior at the runtime. This helps the platform engineers to monitor the infrastructure and detect errors. Since the application is decoupled from the network complexities, it also helps in uniquely identifying when there is an application/service failure. Istio addon Kiali allows you to get a detailed view of service mesh health, monitor infrastructure status, visualize mTLS, and integrate distributed tracing with Jaeger. Let us understand the following types of telemetry that provide service mesh observability.
Traffic Metrics
In a service mesh, it is possible to generate and view proxy-level and service-level metrics. The proxy needs to expose the metrics in a format that can be viewed in the observability tools such as Prometheus, Grafana, etc. In some service mesh, control plane level metrics can also be generated and viewed for self-monitoring.
Traffic trace
The proxy generates the trace spans for the service it proxies for individual requests. The rate and amount of trace generation can be controlled by the platform engineer and it empowers them to understand the service dependencies and sources of latency within the mesh. Many service mesh supports a number of tracing backends like Zipkin, Datadog, etc.
Traffic log
By setting up logs on every data plane in the mesh, platform engineers can monitor from the perspective of an individual workload instance. These logs can be exported directly to the standard output or in OpenTelemetry format.
What are the challenges with using a service mesh?
Having talked about multiple features and use cases where service mesh can be utilized and is really beneficial, it can be sometimes tricky to understand if not configured with the right understanding. The initial challenge is to figure out whether you need a service mesh or not. After that, the problem arises of choosing the right service mesh for your infrastructure. You can make use of the CNCF Landscape Navigator to help you find the right service mesh based on your use case.
Understanding service mesh, configuration, and implementation requires a level of service mesh expertise. Let’s understand some of the challenges being faced by platform engineers while implementing service mesh.
-
Increased complexity: Service mesh sits on top of the application stack. In doing so, if certain configurations are not done after proper optimization, it can lower the performance of the application. For example, in an e-commerce application, while trying to select the option to proceed to pay for items added to the cart, if the timeout for that service is set higher than the optimum value, and the services to process the request are not responding, the customer waiting time for a response will be higher. It can lead to a poor customer experience.
-
Increased resource utilization and operational cost: Service mesh requires a deep level of expertise. There might be a possibility that service mesh is implemented for a possibility that your application may never run into. So that may result in unnecessary utilization of resources. Also, many service meshes have claimed that the proxy would be lightweight, they share the resources of the container or host on which the application is running. This all adds to the resource planning while setting up the infrastructure leading to higher operational costs.
-
Chances of security loophole: With increased complexity, chances increase of misconfiguration. For example, the sidecar identity management requires the certificates of proxy to be automatically rotated if expired. Due to the slightest of network glitches or improper configuration, if the rotation fails it can lead to vulnerabilities and attacks on systems. Once the infrastructure is compromised, it can lead to huge technical debt. This would require manual intervention to address the issues that beat the whole idea of service mesh which is the ease of automation.
Examples of service mesh
Service mesh that offers support to both Kubernetes as well as VMs:
Service mesh that offers to support integration with Kubernetes only:
You can make use of the CNCF Landscape Navigator to help you find the right tool based on your use case. Once you find the service mesh that fits your specific requirements and needs external support for getting started with its adoption, you can check our Istio consulting or Linkerd consulting implementation capabilities.
Conclusion
In this post, we discussed what service mesh is and how it works. We have seen the components of its architecture that contribute to securing the application, optimizing latency, resiliency, and observability.
Before service mesh, companies that dealt with heavy traffic like Netflix, have developed libraries to stop cascading failure and enable resilience in complex distributed systems where failure is inevitable. So companies need a solution to help with service-to-service communication without it being part of the application. Recently, eBPF has been explored by platform engineers as an alternative to the sidecar proxy. It reduces the effort of handling the cloud-native network complexity but it is not easy to create or debug eBPF.
I hope you found this post informative and engaging. For more posts like this one, do subscribe to our newsletter for a weekly dose of cloud-native. I’d love to hear your thoughts on this post, let’s connect and start a conversation on Twitter or LinkedIn.
Frequently Asked Questions (FAQ) about service mesh
-
Q: What are the pros of using a service mesh?
A: With API endpoint discovery and enhanced security, the service-to-service communication in service mesh has reduced latency which leads to better application performance. From the security perspective, you get protection against third-party attacks, flexible access controls, mutual Transport Layer Security (mTLS), and auditing tools. There are much easier traffic control options available that help in various deployments and testing like canary deployments, A/B testing, etc. Developers don’t have to deal with the complexities of working with microservices directly and all is abstracted/taken care of by a service mesh.
-
Q: What is service mesh vs API gateway?
A: Let’s understand this with a banking system example. You have microservices like customer service, account service, and transaction service. The service mesh will ensure secure and reliable communication between these services. It can handle encryption, authentication, and authorization for inter-service communication, making sure that only authorized services can communicate with each other. The API gateway can expose endpoints for clients to perform operations like creating a new account, transferring funds, or retrieving transaction history. It provides a single entry point for all these operations, abstracting the underlying microservices from the clients. Some of the functionality overlap but they are not the replacements to each other.
-
Q: Is service mesh an ingress controller?
A: Ingress controller mostly handles north-south traffic (inward traffic from the outside world) whereas a service mesh facilitates both east-west (the traffic between micro-service within datacenter boundary) and north-south traffic as well. A service mesh can also act as an ingress controller but an ingress controller can’t act as a service mesh. Service mesh is a lot more than an ingress controller. It provides mTLS encryption, authentication and authorization, fault injection, circuit breaking, and observability but the ingress controller can just route the traffic. Ingress controller or traffic routing is one of the features of Service Mesh. Not necessarily one needs both in the architecture. For example - Istio service mesh has an in-built feature called Istio Ingress Gateway, which works as an ingress controller.
-
Q: Is service mesh a load balancer?
A: With most orchestration frameworks you get Layer 4 (transport layer) load balancing but that does not give you a granular control of the traffic. Service mesh gives Layer 7 (Application Layer) load balancing which has better traffic management. You can shift traffic between different services, implement traffic policy, and have traffic telemetry which can help in capturing key metrics like error rate and latency between services.
-
Q: Is service mesh limited to Kubernetes?
A: Service mesh is not limited to only Kubernetes. It can be used outside of Kubernetes clusters as well. However, some of the service mesh tools are Kubernetes native only like Linkerd. Tools like Istio, Kuma, and Consul Connect can be extended outside Kubernetes as well.
-
Q: Does all service mesh have a sidecar?
A: No. Having a sidecar is one way of implementing service mesh. One of the major service mesh’s focuses is to separate the business logic from the network complexities. It could be achieved both with a sidecar as well as without a sidecar. Some of the sidecarless service mesh tools are ambient mesh and cilium mesh.
References
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like