Running Llama 3 with Triton and TensorRT-LLM

In the training phase, a machine learning (ML) model recognizes patterns in the training data and stores these patterns as numerical values called weights (model parameters). These parameters are used to predict an answer when the model is given new input data or a question.
For example, when you ask a question to ChatGPT or any other Large Language Model (LLM), it generates the answer for you. Other ML models are used to detect fraud transactions, image or even audio classification, and so on. These are examples of inference, where the ML model generates or predicts the answer based on the training data. For the inference to run, we need inference servers!
In this blog post, we will briefly examine inference and inference servers, take a look at a popular inference server Triton, and then deploy the Meta’s Llama 3 model (an LLM) using it.
Need for inference servers
Training involves the effort of using ML algorithms to build a model and then fine-tuning it for a specific task using a dataset. While this may be seen as a one-time process, it often requires an iterative process to improve the model performance, resulting in new versions. In contrast, inference is the ongoing process where the model is presented with different inputs to interpret and predict the output. Typically, a model spends more time in inference compared to training.
Running the models at scale for inference, where they are queried by various users and services, has some unique challenges:
- Latency: Given the huge size of models, especially LLMs, the response times can be longer. Having low latency is critical if you are developing a chat application. On the other hand, some batch workloads running asynchronously can tolerate more latency.
- Resource utilization: ML models are often resource-intensive, requiring more CPUs and costly hardware accelerators like GPUs. So it becomes important to ensure that the available hardware resources are fully utilized, reducing per-inference costs. This can be done by running multiple models in parallel and batching multiple requests together.
- Support for different models: Complex applications utilize pipelines of different models working together to achieve the desired outcome. Also, different teams might use different models and frameworks. This can become tricky for the infrastructure team to manage and optimize for each framework.
That’s where inference servers come into the picture. Inference servers load ML models into GPU memory and provide various approaches to running them efficiently at scale. These include running multiple instances of the models in parallel, batching and scheduling the requests, and so on. These servers provide interfaces like HTTP, gRPC, and client libraries to communicate with the deployed models. And also provide standard observability metrics like queue size, latency, CPU/GPU utilization, etc.
Additionally, these inference servers support multiple framework backends like TensorRT-LLM, vLLM, and more. These backends implement hardware and software-based performance optimizations for models, which help reduce latency and play a big role in inference servers. To learn more about inference, check out our blog post on AI model inference.
Workflow for running Triton with TensorRT-LLM
We will be deploying Meta’s Llama 3 8B using the Triton Inference server with TensorRT-LLM backend. The workflow of doing this involves the following steps:
- Convert the weights downloaded from Hugging Face Hub to TensorRT-LLM checkpoints.
- Compile the checkpoints into a TensorRT engine.
- Load the engine into the TensorRT-LLM model runner and run it locally or via the TensorRT-LLM backend for Triton Inference server.
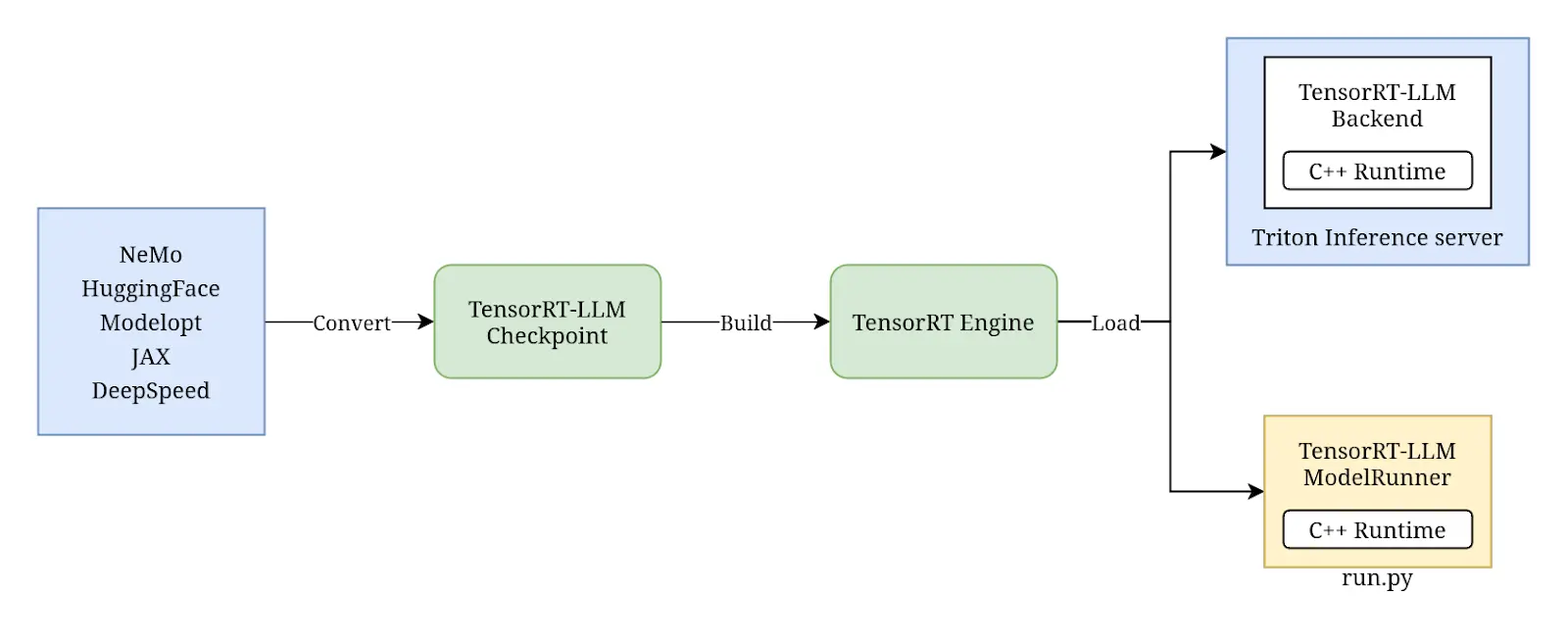
We will cover each step in detail as we perform them. You can read more in TensorRT-LLM Architecture.
Prerequisites
Before we get started, here are the prerequisites to follow along with this tutorial.
-
A machine or virtual machine with at least 8 CPUs and a GPU with 24GB of RAM. To find resource requirements for a model, see Can You Run It? LLM version.
We are using a g6.2xlarge instance on AWS having 8 vCPUs and L4 Tensor Core GPU with 24GB of memory. - Around 300GB of disk space to store the model weights and all the container images.
-
NVIDIA container runtime installed, as we will be running tools within Docker containers.
We are using the Deep Learning Base AMI with Ubuntu 22.04, which has NVIDIA container runtime and other required tools installed. - Llama 3 is distributed under a community license agreement, so you will need to request access on Hugging Face and provide a token while cloning the model.
Get the model weights
We will download the instruction-tuned variant of Llama 3 with 8 billion parameters from Hugging Face Hub. Hugging Face hosts the model weights as Git repositories, with large files stored using Git LFS.
Run the following commands to set up Git LFS for your user, and then clone the model.
sudo apt-get update && sudo apt-get -y install git-lfs
git lfs install
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
Once the git clone command completes, the directory should look like this:
$ du -sh Meta-Llama-3-8B-Instruct
60G Meta-Llama-3-8B-Instruct
$ du -sh Meta-Llama-3-8B-Instruct/*
30G .git
4.0K config.json
4.0K generation_config.json
4.7G model-00001-of-00004.safetensors
4.7G model-00002-of-00004.safetensors
4.6G model-00003-of-00004.safetensors
1.1G model-00004-of-00004.safetensors
24K model.safetensors.index.json
15G original
4.0K special_tokens_map.json
8.7M tokenizer.json
52K tokenizer_config.json
# …
Usually, these model repositories contain the model weights, tokenizer files, and a config.json.
- Model weight tensors (multidimensional arrays) are stored in formats like Safetensors.
- Tokenizer and its related configuration files are used to segment the natural language inputs into tokens, which are numerical representations that models can work with.
config.jsoncontains details about the pre-trained model like its architecture, size of the model, vocabulary size (tokens), layers, and other hyperparameters required to load the model weights correctly.
Now that we have the model weights downloaded, we need to convert them to the TensorRT-LLM checkpoint format.
Using TensorRT-LLM
TensorRT-LLM is an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM contains components to create Python and C++ runtimes that execute those TensorRT engines. It also includes a backend for integration with the NVIDIA Triton Inference Server.
The optimization techniques for LLMs are rapidly evolving, so it becomes hard to select appropriate ones for a model. The library and helper scripts provided by TensorRT-LLM help in optimizing the LLMs with the right techniques so that they run efficiently despite being large in size. Some examples of these techniques are quantization, kernel fusion, runtime optimizations like KV caching, continuous in-flight batching, etc. Read more about TensorRT-LLM in the documentation.
TensorRT-LLM has built-in support to optimize various well-known models. We will be using the Llama support to optimize the downloaded Llama 3 model. You can find more details about the Llama support in the examples/llama directory on GitHub. It has a bunch of example commands for optimizing and running Llama models.
In order to build a TensorRT engine that will be run by the C++ runtime, we first need to convert the model weights into TensorRT-LLM checkpoints. There are two ways to do this:
- Use the model-specific
convert_checkpoint.pyfile, which has support for some quantization techniques. - Use
quantize.pywhich uses the quantization toolkit Modelopt (previously known as AMMO) to quantize the model. The generated checkpoints are supported by TensorRT-LLM.
We will be using the quantization approach to get TensorRT-LLM checkpoints. To learn more about quantization, check out the Quantization section of the AI Model Inference post.
Setup TensorRT-LLM
We will clone the TensorRT-LLM repository first:
git clone -b v0.9.0 https://github.com/NVIDIA/TensorRT-LLM.git
Now, set up a Docker container with all the dependencies. Using the container simplifies the environment configuration, it comes preinstalled with base tools.
# Ref: https://nvidia.github.io/TensorRT-LLM/installation/linux.html
# Obtain and start the basic docker image environment. (Modified according to requirements of quantize.py)
docker run --rm --runtime=nvidia --gpus all \
--entrypoint /bin/bash \
--ipc=host --ulimit memlock=-1 --shm-size=20g \
--volume $(pwd):/data --workdir /data \
-it nvidia/cuda:12.4.0-devel-ubuntu22.04
# Install dependencies, TensorRT-LLM requires Python 3.10
apt-get update && apt-get -y install python3.10 python3-pip openmpi-bin libopenmpi-dev
# Install the stable version of TensorRT-LLM (corresponding to the cloned branch).
pip3 install tensorrt_llm==0.9.0 -U --extra-index-url https://pypi.nvidia.com
Next, we will install the requirements of quantize.py.
# Ref: https://github.com/NVIDIA/TensorRT-LLM/tree/v0.9.0/examples/quantization
# Install Modelopt (AMMO)
pip install --no-cache-dir --extra-index-url https://pypi.nvidia.com nvidia-ammo~=0.7.3
# Install the additional requirements
cd TensorRT-LLM/examples/quantization
# Cython is required by a transitive dependency
pip install Cython
pip install -r requirements.txt
With all the prerequisites out of the way, let’s quantize our model. This is also called post-training quantization (PTQ), as it is done on pre-trained model weights.
Quantize the model
We will use quantize.py to apply AWQ: Activation-aware Weight Quantization (paper) on our model. This technique preserves a small percentage of the weights crucial for the LLM’s accuracy. This will reduce the memory footprint of Llama 3 8B significantly.
python3 quantize.py --model_dir /data/Meta-Llama-3-8B-Instruct \
--output_dir /data/Meta-Llama-3-8B-Instruct-awq \
--dtype bfloat16 \
--qformat int4_awq \
--awq_block_size 128 \
--batch_size 12
Here is a summary of command line flags:
dtypeis the data type used to store the model weights i.e.bfloat16. You can find this in config.json astorch_dtype.qformatis the quantization format INT4 AWQ in our case.awq_block_sizeis the group size used during AWQ. The quantization happens in groups, and important weights in each group are preserved. 128 is usually recommended.batch_sizedetermines how many batches are processed in parallel. Bigger the number, more memory utilization and faster processing. If you gettorch.cuda.OutOfMemoryError: CUDA out of memory.error while running the command, try to reduce this number.
The output in the Meta-Llama-3-8B-Instruct-awq will be a config.json and .safetensors files having the quantized weights of our model. The command took about 5 minutes to complete on our machine, and the resulting directory is about 5.5GiB in size.
# du -h Meta-Llama-3-8B-Instruct-awq/*
4.0K config.json
5.5G rank0.safetensors
You can notice that more details about the quantization and its configuration got added to the config.json.
{
"producer": {
"name": "ammo",
"version": "0.7.4"
},
"quantization": {
"quant_algo": "W4A16_AWQ",
"kv_cache_quant_algo": null,
"group_size": 128,
"has_zero_point": false,
"pre_quant_scale": true,
"exclude_modules": [
"lm_head"
]
}
"note": "other details are elided for brevity"
}
Build the TensorRT engine
Now we will compile the checkpoints into a TensorRT engine that will be specifically optimized for the GPU(s) on our machine.
trtllm-build \
--checkpoint_dir /data/Meta-Llama-3-8B-Instruct-awq \
--gpt_attention_plugin bfloat16 \
--gemm_plugin bfloat16 \
--output_dir /data/llama3-engine
Quoting the TensorRT-LLM documentation sections Compile the Model into a TensorRT Engine and TensorRT Compiler; emphasis and links mine:
When you created the model definition with the TensorRT-LLM API [which was done by the developers of TensorRT-LLM while adding support for Llama models], you built a graph of operations from NVIDIA TensorRT primitives that formed the layers of your neural network. These operations map to specific kernels; prewritten programs for the GPU.
The TensorRT compiler can sweep through the graph to choose the best kernel for each operation and available GPU [on the machine]. Crucially, it can also identify patterns in the graph where multiple operations are good candidates for being fused into a single kernel. This reduces the required amount of memory movement and the overhead of launching multiple GPU kernels.
TensorRT also compiles the graph of operations into a single CUDA Graph that can be launched all at one time, further reducing the kernel launch overhead.
The TensorRT compiler is extremely powerful for fusing layers and increasing execution speed, but there are some complex layer fusions — like FlashAttention — that involve interleaving many operations together and which can’t be automatically discovered. For those, you can explicitly replace parts of the graph with plugins at compile time [specified as flags to the
trtllm-buildcommand].
We have enabled the gpt_attention plugin, which enables a FlashAttention-like fused attention kernel. GEMM (General Matrix Multiplications) plugin is also enabled, which uses NVIDIA cuBLASLt to perform GEMM operations, resulting in better performance and reduced GPU memory usage.
In the console log, you can see that many plugins are automatically enabled for our Llama model, which is supported out of the box.
[TensorRT-LLM] TensorRT-LLM version: 0.9.0
[07/11/2024-10:46:32] [TRT-LLM] [I] Set gpt_attention_plugin to bfloat16.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set gemm_plugin to bfloat16.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set nccl_plugin to float16.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set context_fmha to True.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set paged_kv_cache to True.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set remove_input_padding to True.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set use_custom_all_reduce to True.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set multi_block_mode to False.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set enable_xqa to True.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set attention_qk_half_accumulation to False.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set use_paged_context_fmha to False.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set use_fp8_context_fmha to False.
[07/11/2024-10:46:32] [TRT-LLM] [I] Set use_context_fmha_for_generation to False.
# …
[07/11/2024-10:47:14] [TRT-LLM] [I] Serializing engine to /data/llama3-engine/rank0.engine...
[07/11/2024-10:47:27] [TRT-LLM] [I] Engine serialized. Total time: 00:00:13
[07/11/2024-10:47:28] [TRT-LLM] [I] Total time of building all engines: 00:00:55
The output of the above command is stored inside the llama3-engine directory. It consists of two files:
rank0.engineis the TensorRT engine, which has model weights and other information required to execute the model.config.jsonhas all the details of the model before running the build, as well as details of all the plugins used for compiling the engine.
# du -sh /data/llama3-engine/*
8.0K config.json
5.4G rank0.engine
Learn more about the TensorRT-LLM plugins
All the available command line flags and plugins can be quite intimidating at first. Go through the following resources sequentially to understand them better.
- Take a look at
trtllm-build --helpto know the list of parameters. - examples/llama has details about plugins enabled by default, along with other examples.
- Best Practices for Tuning the Performance of TensorRT-LLM — tensorrt_llm documentation
- Multi-Head, Multi-Query, and Group-Query Attention — tensorrt_llm documentation
Running the model locally
Though the engine file has everything we need to execute the model, running LLMs require multiple passes through the model. TensorRT-LLM includes a C++ runtime for executing the model engines; it takes care of KV cache, batching the requests together, and more.
To test the model locally, run the following command:
python3 ../run.py \
--engine_dir=/data/llama3-engine \
--max_output_len 200 \
--tokenizer_dir /data/Meta-Llama-3-8B-Instruct \
--input_text "How do I count to nine in Hindi?"
Expect an output similar to the following:
Input [Text 0]: "<|begin_of_text|>How do I count to nine in Hindi?"
Output [Text 0 Beam 0]: " Counting to nine in Hindi is easy and fun. Here's how you can do it:
1. एक (ek) - one
2. दो (do) - two
3. तीन (teen) - three
4. चार (chaar) - four
5. पांच (paanch) - five
6. छ (cha) - six
7. सात (saat) - seven
8. आठ (aat) - eight
9. नौ (nau) - nine
So, counting to nine in Hindi is easy. Just remember the numbers and you're good to go!"
You can exit the container now. After testing the model locally, we will deploy it using Triton to make it available to multiple users over HTTP, gRPC, etc. We will use the TensorRT-LLM backend for Triton, which uses the same C++ runtime.
Triton Inference Server
Triton Inference server can be used for the production deployment of models. Triton supports various deep learning and machine learning frameworks like TensorFlow, PyTorch, ONNX, TensorRT, Python, and more. It can manage model repositories along with their versions, run the models concurrently, do dynamic batching, scheduling, etc. It allows you to create complex pipelines involving multiple models. Triton exposes metrics like GPU utilization, throughput, latency, and so on. All these features make the model deployments production-ready.
Create a model repository
We will create a model repository with the help of the tensorrtllm_backend Git repository from the Triton project. The model repository holds all the model files, as well as any other metadata needed to load them.
git clone -b v0.9.0 https://github.com/triton-inference-server/tensorrtllm_backend.git
# Create model repository with files from above Git repo
mkdir -p repo/llama3
cp -r tensorrtllm_backend/all_models/inflight_batcher_llm/* repo/llama3/
cp llama3-engine/* repo/llama3/tensorrt_llm/1/
# Remove BLS model (unused)
rm -r repo/llama3/tensorrt_llm_bls
In the repo/llama3 directory, we have four subdirectories i.e. models:
preprocessingandpostprocessingmodels use the Python backend. These use the tokenizer files from the Llama 3 model to convert the input strings to token IDs, and then output token IDs from the model to strings.tensorrt_llmis the wrapper on the engine, it is used for inference.ensembleis used to chain thepreprocessing,tensorrt_llm, andpostprocessingmodels together. This is the model we will send our prompt to.
Each model in our repository has a configuration file config.pbtx that holds various parameters for that model. As these are template configuration files, we need to replace some parameters with the correct values. For example, the path to engine and tokenizer files, memory allocation for KV cache, in-flight batching configuration, and so on.
# Paths are for Triton container we will run in next steps
# Ref: https://github.com/triton-inference-server/tensorrtllm_backend/blob/v0.9.0/docs/llama.md
HF_LLAMA_MODEL="/data/Meta-Llama-3-8B-Instruct"
ENGINE_PATH="/data/repo/llama3/tensorrt_llm/1"
python3 tensorrtllm_backend/tools/fill_template.py -i repo/llama3/preprocessing/config.pbtxt tokenizer_dir:${HF_LLAMA_MODEL},tokenizer_type:auto,triton_max_batch_size:1,preprocessing_instance_count:1
python3 tensorrtllm_backend/tools/fill_template.py -i repo/llama3/postprocessing/config.pbtxt tokenizer_dir:${HF_LLAMA_MODEL},tokenizer_type:auto,triton_max_batch_size:1,postprocessing_instance_count:1
python3 tensorrtllm_backend/tools/fill_template.py -i repo/llama3/ensemble/config.pbtxt triton_max_batch_size:1
python3 tensorrtllm_backend/tools/fill_template.py -i repo/llama3/tensorrt_llm/config.pbtxt triton_backend:tensorrtllm,triton_max_batch_size:1,decoupled_mode:False,max_beam_width:1,engine_dir:${ENGINE_PATH},max_tokens_in_paged_kv_cache:2560,max_attention_window_size:2560,kv_cache_free_gpu_mem_fraction:0.5,exclude_input_in_output:True,enable_kv_cache_reuse:False,batching_strategy:inflight_fused_batching,max_queue_delay_microseconds:0
You can find more details about these parameters in the Modify the model configuration section. Also, an in-depth explanation of these parameters can be found in Model Configuration.
Run the Triton Inference server
We will run the Triton Inference server using the container image from the NGC catalog. The images with trtllm in their tag have the TensorRT-LLM backend bundled with them.
# Ref: https://github.com/triton-inference-server/tensorrtllm_backend/#launch-triton-server
docker run --rm -it --net host --gpus all \
--shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 \
-v $(pwd):/data \
nvcr.io/nvidia/tritonserver:24.05-trtllm-python-py3 \
tritonserver --model-repository=/data/repo/llama3
The server logs, after successfully loading all the models, would look like this:
I0711 12:03:03.837014 1488 grpc_server.cc:2463] "Started GRPCInferenceService at 0.0.0.0:8001"
I0711 12:03:03.837401 1488 http_server.cc:4692] "Started HTTPService at 0.0.0.0:8000"
I0711 12:03:03.878746 1488 http_server.cc:362] "Started Metrics Service at 0.0.0.0:8002"
A note about versions of Triton, TensorRT, and TensorRT-LLM
TensorRT-LLM has support for a specific version of TensorRT. An engine built for one version of TensorRT is not compatible with older versions. Also, each version of Triton has support for a specific version of TensorRT-LLM.
To avoid any compatibility issues with these three tools, it is recommended to build the engine using the Triton image which will be used in the final deployment. The tritonserver:yy.mm-trtllm-python-py3 images have the supported version of TensorRT-LLM and TensorRT preinstalled. You can find the TensorRT-LLM version in the release notes of Triton under the “Triton TRT-LLM Container Support Matrix” section, and use the scripts from the corresponding version tag on the TensorRT-LLM repository. We have used a separate image to build the engine so that we can show the steps of installation and setup.
Send request to server
Let’s send an inference request to the generate endpoint of the server running on HTTP port 8000:
# Ref: https://github.com/triton-inference-server/tensorrtllm_backend/tree/v0.9.0/#query-the-server-with-the-triton-generate-endpoint
curl -X POST http://localhost:8000/v2/models/ensemble/generate -d \
'{"text_input": "What is machine learning?", "max_tokens": 20, "bad_words": "", "stop_words": ""}'
Notice that we have passed 4 input parameters, which are defined in the ensemble model’s config.pbtx. The output would look as follows:
{
"text_output": " Machine learning is a subset of artificial intelligence (AI) that involves training algorithms to learn from data and",
"context_logits": 0.0,
"cum_log_probs": 0.0,
"generation_logits": 0.0,
"model_name": "ensemble",
"model_version": "1",
"output_log_probs": [0.0, 0.0, 0.0, 0.0, 0.0],
"sequence_end": false,
"sequence_id": 0,
"sequence_start": false
}
You can get a detailed overview of using the generate endpoint in the TensorRT-LLM backend repository. Similarly, there are client libraries that can be used to talk to the Triton server, you can read more about them at Triton Client Libraries and Examples.
Conclusion
With LLMs and other machine learning models becoming an integral part of applications, it’s crucial to be able to run the inference within our own infrastructure.
The optimization techniques for LLMs are evolving rapidly. TensorRT-LLM helps us choose the correct set of software and hardware optimization techniques specifically for NVIDIA GPUs. Triton, on the other hand, enables us to deploy production-ready inference servers with complex architecture to support our application’s needs. Navigating these evolving technologies and implementing them effectively can be challenging. For production grade setup, feel free to contact our AI & GPU Cloud experts for help.
If you found this post useful and informative, subscribe to our weekly newsletter for more posts like this. I’d love to hear your thoughts on this post, so do start a conversation on LinkedIn
What’s next?
Make sure you go through all the links from this blog post first, then check out these resources to get started with TensorRT-LLM and Triton.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like