
Kiam for Pod IAM access in EKS

When it comes to authentication and authorization in AWS, IAM (Identity & Access Management) is a crucial component. If you are utilizing EKS (Elastic Kubernetes Service – managed Kubernetes from AWS), granting IAM access to pods can make things simpler for migrating existing applications. There are a few reasons why IAM access in pods is important:
- Pods need AWS resources but, they are ephemeral and can’t rely on nodes for that. For example, one pod might be on node A now and might be on node B a few hours later.
- Applications running inside pods need access to AWS resources such as creating or deleting an S3 bucket, launching EC2 instances which would require additional work without adequate IAM access.
- Using IAM roles inside pods also ensure per application credentials which is more secure architecture.
In AWS, IAM roles are attributed through instance profiles and are accessible by services through the usage of aws-sdk of EC2 metadata API. While using the aws-sdk, a call is made to the metadata API which provides temporary credentials and is used to access AWS services. This model breaks in Kubernetes/EKS world as a single node might be scheduling more than one application. Thes application might require different access altogether – so using instance profiles is not a good option. It would be ideal to provide the relevant access only to the application pod and not the entire host. There are a few solutions that try to bridge this gap such as:
- Kiam by uSwitch
- Kubernetes-external-secrets implementation by GoDaddy
- AWS Service Broker
- kube2iam
Let’s discuss each one with a quick overview and then dive deeper into one of them.
kube2iam
kube2iam is one of the widely used frameworks. kube2iam, provides IAM credentials to containers running inside a Kubernetes cluster based on the pod annotations (used to identify things not used internally by Kubernetes).
- It works by deploying a pod on every node as a DaemonSet in the Kubernetes cluster.
- Runs in the host network with required privileges and security access to intercept calls on the EC2 metadata API on each node
- The pods on each node intercept call to the API and assume roles which are assigned to pods in the cluster via annotations.
- The only permission required by nodes is the ability to assume the roles which are used by pods.
Pros:
- No code changes are required if the default instance credentials provider chain is being used in AWS clients.
- Improves overall security by restricting IAM access. With nodes needing only the roles which are to be used by pods rules out the possibility of a suspicious pod pre-assuming the whereabouts of an IAM role.
- Namespace based restrictions are also supported like configuring a namespace and allowing certain roles to be assumed in that particular namespace by pods.
- Has support with network implementations like Calico, CNI, EKS, flannel, OpenShift
Cons:
- Due to the increased load, applications may result assuming incorrect credentials with proxy issuing another role’s credentials to the application.
- There is no prefetching of credentials which adds to the response time in fetching roles from IAM and being assumed by pods. This could highly affect start latency and post hindrance to reliability.
Kubernetes External Secrets
Implementation of Kubernetes External Secrets by the engineering team at GoDaddy was an outcome to enhance fetching of secrets from Secrets Manager in AWS when the application starts. It utilizes Kubernetes external secrets system (like AWS Secrets Manager) to securely add secrets inside Kubernetes cluster.
- Creates ExternalSecrets object using Custom Resource Definition and a controller inside a Kubernetes cluster.
- The declared ExternalSecret resource fetches the secret data with controller converting all the external secrets to secrets inside the Kubernetes cluster.
- The pods can then utilize the secrets to access AWS resources inside the cluster.
Pros:
- Instead of defining a base64 encoded data in a secret object, an ExternalSecret object is created specifying the secret management system.
- Easy to set up with a single command using kubectl to create required resources for External Secrets to work in the EKS cluster.
Cons:
- It doesn’t really help in assuming IAM roles for the pods. Instead, creates secrets as per the existing secrets inside AWS Secrets Manager.
- Doesn’t give much clarity on restricting access to potential attacks that might try to leak secrets
AWS Service Broker
AWS Service Broker is an implementation of OSB (Open Service Broker) API which allows us to provision AWS services like RDS, EC2 directly through platforms like Kubernetes, OpenShift.
AWS Service Broker provides a catalog of AWS services that can be managed and connected to applications running inside the EKS cluster using Kubernetes APIs and tooling.
Pros:
- Utilizes Kubernetes APIs and Kubernetes Service catalog to advertise required AWS services to the EKS platform. It is the Kubernetes Service catalog which communicates with the AWS Service Broker when managing AWS Services.
- Can launch proper AWS Services into the AWS account with correct permissions using AWS SDK Credential Provider Chain
Cons:
- Setup is not as easy as compared to kube2iam or Kiam. Requires aws cli for installing AWS Service Broker & Kubernetes Service Catalog inside the Kubernetes cluster.
- It uses AWS CloudFormation to manage the lifecycle of any resources created in the AWS account. So, a separate role has to be configured which will be assumed by CloudFormation while creating a service.
Kiam
Kiam runs as an agent on each node in Kubernetes cluster and allows cluster users to associate IAM roles to pods. By utilizing AWS Security Token Service (STS) it makes easy to assign short-lived AWS security credentials to pods ensuring per-application credentials with IAM roles. It has two components: server and agent which are scheduled separately on the nodes in the Kubernetes cluster.
Pros:
- It helps in restricting IAM access in a clean and elegant way by using STS.
- Namespace restrictions are not only supported but a required feature in Kiam.
- Also restricts access to EC2 metadata API by default, denying access to pods to other metadata API paths. This restricts pods to discover information about the node they are running on.
- Prefetches credentials to be utilized by the pods faster which gives it an edge in terms of performance.
Cons:
- Support for configuring network layer, cluster configuration comes with few options and are also not well documented.
- Setup is not easy and requires a bit more involvement.
Why Kiam?
With Kiam, only the nodes running server need direct IAM access and the nodes running agent (worker nodes) only need to connect to the server to get IAM access. It not only supports namespace based restrictions but makes it a requirement. So, the namespace where the desired pod needs to be configured to assume a role must configure the list of allowed roles with regex. It has a feature to set --assume-role-arn flag which gives an additional layer of IAM security specifying a role that the server pods will assume before they handle IAM requests.
Kiam Features
Kiam offers the following:
- No client SDK modifications are needed. Kiam intercepts metadata API requests.
- Increased security by splitting the process into two server & agent. In that case, only server process are permitted to perform sts:AssumeRole
- Prefetching credentials from AWS which reduces response time as observed by SDK clients.
- Load balancing requests across multiple servers which helps in deploying updates to servers without breaking agents.
- Multi-account IAM support. Pods can assume roles from any AWS account assuming trust relationship permits it
- Text and JSON log formats
Kiam Architecture
Kiam has two components – the server and the agent which together enable interacting with AWS.
Agent:
The agent is deployed as a DaemonSet on every worker node. Running as DaemonSet ensures each node runs a copy of agent pod which acts as a proxy for the metadata API and as a new node is added into the cluster the agent pods are added to them. The agent runs in the host network with privileged security access so that it can create iptables rule to on the node to intercept calls to EC2 metadata API at 169.254.169.254 which is used by AWS SDKs to authenticate with IAM.
- The agent runs an HTTP proxy which intercepts credential requests and passes on anything else.
- A DNAT iptables rule is required to intercept the traffic. The agent is capable of removing or adding the rule by the use of
--iptablesflag
Server:
This process is responsible for connecting Kubernetes API Servers to watch Pods and communicating with AWS STS credentials to request credentials. Kiam server is essentially a prefetched cache of temporary IAM authorization used by the agent.
- Kiam server can be run on a subset of nodes (usually Kubernetes master nodes), further restricting access to IAM in the Kubernetes cluster.
- By prefetching credentials, it also reduces calls to IAM overall and reduces latency for most authorization calls as we do not have to wait for authorization call to take place initially when the credentials have expired.
- No code changes are needed if the default or instance credential provider chain is used in the AWS clients.
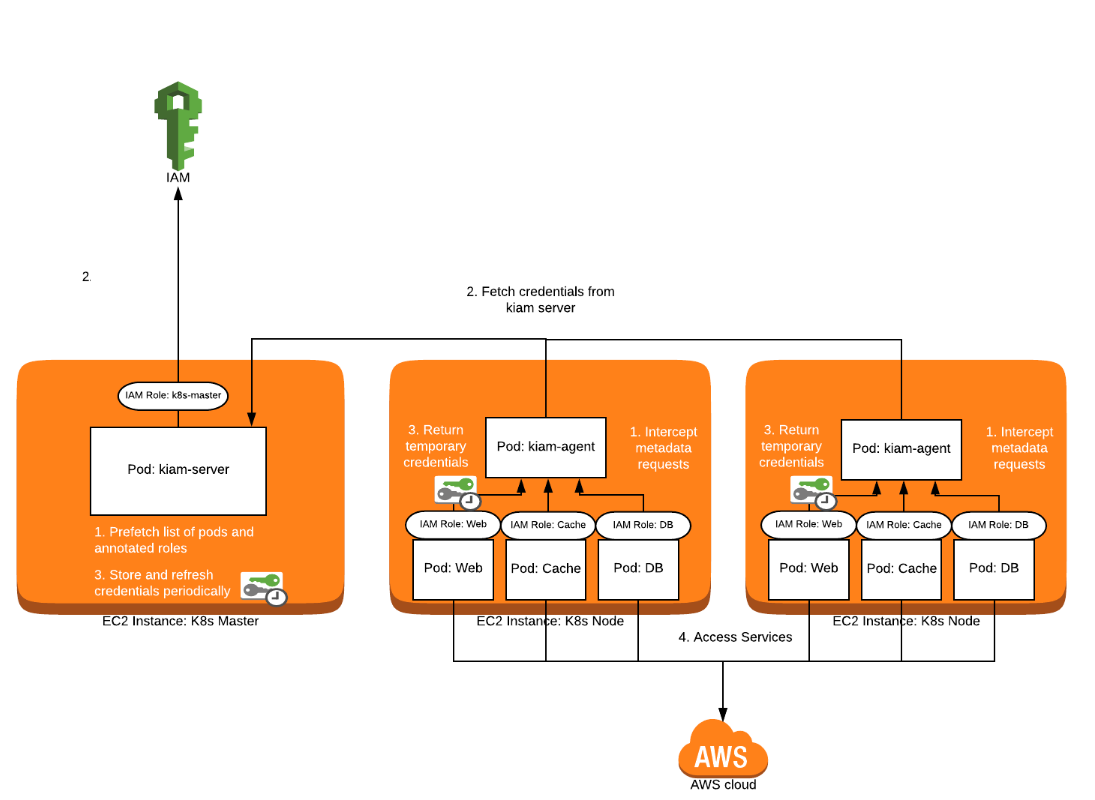
Image Credits: Blue Matador, Inc.
Enabling Kiam in EKS cluster
As mentioned above, the two components of Kiam are server and agent. Both server and agents run as DaemonSets inside an EKS cluster and create the following resources once scheduled:
- DaemonSets for kiam-server and kiam-agents in kube-system
- Service for kiam-server in kube-system
- ServiceAccount for kiam-server with cluster role for kiam-read, kiam-write and respective ClusterRoleBinding.
- The recommended way to schedule kiam-server processes is on Kubernetes master nodes but, in case of EKS master nodes are hidden. So we can’t create a trust relationship for kiam-server role with the node instance profile of master nodes. So in this case, we can have a dedicated node-instance group where we schedule our Kiam server processes. This is achieved using specific labels to separate out nodes running kiam-server and kiam-agent processes. We can apply taints and tolerations so that no other but the pods which satisfy tolerations are scheduled on those nodes.
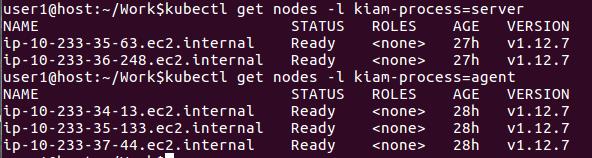
This can be edited in the kiam-server and kiam-agent yaml manifests under .spec.template.spec :
for server,
nodeSelector:
kiam-process: server
for agent,
nodeSelector:
kiam-process: agent
$ kubectl get daemonset --selector app=kiam --namespace kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
kiam-agent 3 3 3 3 3 role=kiam-agent 28h
kiam-server 2 2 2 2 2 role=kiam-server 28h
- On deploying agent inside EKS cluster, the host CNI interface has to be mentioned as
--host-interface=!eth0inside.spec.template.spec.containers.argsif amazon-vpc-cni-k8s network plugin is been used. - Also
.spec.template.spec.volume.hostPath.pathvalue has to be/etc/pki/ca-trust/extracted/pem/for ‘Amazon Linux 2’ for both agent and server resources. - For Kiam to work, each node where Kiam server is running would need sts: AssumeRole policy so that the respective credentials can be used by the pods scheduled on the nodes running Kiam agents. Also, the role which is to be assumed by the server should have a trust relationship with the IAM role of kiam-server node instance group.
- Annotate your pods with
iam.amazonaws.com/role: <role_name> - All the namespaces must have an annotation with a regular expression which roles are permitted to be assumed in that namespace –
iam.amazonaws.com/permitted: ".*" - For the server to communicate with the agent, TLS has to be configured and required assets must be created. This ensures that only agent can communicate with the server to get the credentials.
- Create a pod in the permitted namespace for the role which is to be assumed by annotating it with `iam.amazonaws.com/role:
`. Once the pod is created, you can verify the access.
How Kiam Works
Kiam uses client-go cache package to create a process which uses two mechanisms (via the ListerWatcher interface): watcher and lister for tracking pods.
Watcher: the client tells the API server which resources it’s interested in tracking and the server will stream updates as they are available.
Lister: this performs a List which retrieve details about all the running pods.
Kiam uses an index to be able to identify pods from their IP addresses. Once Kiam becomes aware of pods, details are stored in a cache which helps in faster retrieval of relative pod information. If any information related to a pod is not available in the cache which means that details from the watcher are not yet delivered to the server. Inside the agent, included are some retry and backoff behavior which keeps on checking for pod details in the cache.
Looking for help with Kubernetes adoption or Day 2 operations? learn more about our capabilities and why startups & enterprises consider as one of the best Kubernetes consulting services companies.
References & further reading
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like







