AI Cloud Architecture: A Deep Dive into Frameworks and Challenges

Integrating AI in cloud architecture has enabled businesses to handle AI/ML workloads effectively. The integration supports complex workloads that demand high computing power and complex hardware specifications to meet the dynamic and evolving demands of businesses. Although AI cloud architecture is transforming and driving the businesses to new levels, businesses face multiple challenges when they try to leverage the combination of AI/ML operations for their challenging workloads, such as high computation, large datasets, and the necessity of specific hardware like Graphical Processing Units (GPUs) and Tensor Processing Units (TPUs).
In this blog post, we’ll discuss the basic architectural patterns you need to know to run AI workloads in the cloud, including model training and serving/inference architectures, machine learning operations (MLOps) architectures, edge-cloud hybrid platforms, and architectural design frameworks. Additionally, we will explore the trends that will most likely define the future of AI in cloud architecture.
Fundamental AI workload patterns
AI workloads involve processing large datasets, training models, and serving predictions that demand high computational power and memory. Before exploring AI cloud architectures, it is important to understand the key workload patterns and how they interact with cloud infrastructures.
Primary AI workloads
AI workloads are primarily classified into two types, training and inference.
Training workloads: This architectural workload defines the task of feeding data into an AI/ML model in order to learn patterns and adjust its internal parameters.
- Runs on a single machine or scales across multiple machines using distributed training architectures
- Requires high computing resources (like GPU, memory, and storage) to handle large datasets and complex models
- Introduces high latency due to iterative optimization processes and convergence cycles
- Improves accuracy through repeated fine-tuning and model updates
- Single node training runs all the operations in a single node or device; ideal for small datasets
- Distributed training is ideal for models that are too large to fit on a single device.
Once trained, these models are deployed to perform inference operations.
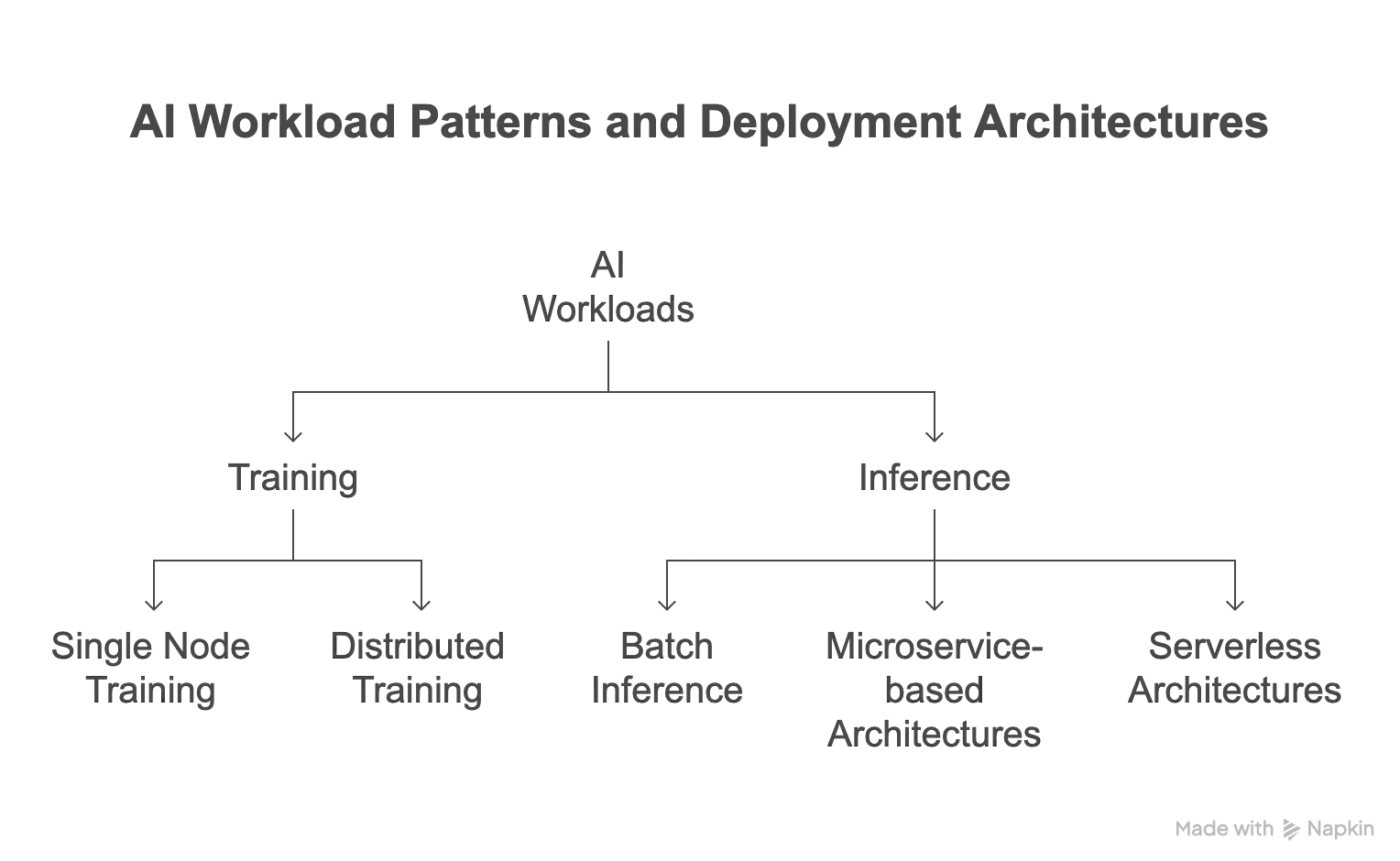
Inference workloads: In this workload type, trained models are used to make predictions on new, unseen data, as well as real-time data. Model serving architectures and frameworks are critical in deploying and managing these models effectively.
- Requires lower computational resources compared to training workloads
- Prioritizes low latency and high throughput for real-time predictions
- Supports simplified deployment and management of inference workflows \
Common serving architectures include:
- Batch inference: Generating predictions for a large batch of data all at once.
- Microservice-based architectures: Deploying models as independent services that can be separately scaled and managed.
- Serverless architectures: Hosting models through serverless platforms that manage infrastructure management and scaling dynamically.
Common model serving frameworks are:
- TorchServe: Optimized for PyTorch models with features that include dynamic batching and multi-model serving.
- Triton inference server: Supporting multiple deep learning frameworks with GPU-accelerated models.
- TensorFlow Serving: Built specifically for serving TensorFlow models with extensive flexibility..
Read our blog post on exploring AI model inference to discover more about inference workloads, model serving patterns, and optimization techniques.
Processing patterns
Some workloads involve processing huge amounts of data in batches, whereas others involve instant processing in order to provide real-time insights. The choice of processing patterns has a considerable impact on the efficiency and usage of these workloads. AI workloads can be further classified into two primary patterns:
Batch processing: Batch processing involves managing large volumes of data in groups or batches, which allows for more efficient use of computational resources and optimizes overall processing time, making it appropriate for scenarios that do not require real-time information.
For example, suppose an e-commerce platform gets orders from customers throughout the day. Rather than completing each order when it is placed, the system could complete all orders at the end of each day and pass them in one batch to the order fulfillment group.
Key characteristics of batch processing:
- Requires high computational power for processing large batches
- Typically executed through distributed processing platforms like Apache Spark and Hadoop, or managed services such as AWS Batch
- Suitable for model training workloads and periodic model updates
Real-time processing: Real-time processing involves handling data with minimum delay, ensuring instant predictions or decisions.
For instance, within financial institutions, an event processing system can be used to track real-time financial transactions for fraudulent behavior. Through analysis of the data in real time, the system can trigger a security alert to security staff if it identifies any suspicious activity, enabling them to investigate and avoid financial loss quickly.
Key characteristics of real-time processing:
- Low latency that ensures data gets processed and predictions are returned in milliseconds or seconds.
- Frameworks like Apache Kafka, Apache Flink, Spark, and Google Cloud Dataflow are widely used.
- Critical for applications that require immediate response, such as fraud detection or personalized recommendations.
Model training architectures
Model AI training architecture designs have evolved to meet the computational and operational needs of ML workloads, particularly for large and complex models. Depending on the size, complexity of the model, and dataset requirements, training can be performed using the following two approaches:
- Single-node training architecture: Model training is conducted on a single high-performance GPU- or TPU-enabled machine to facilitate small models or datasets.
- Distributed training architecture: Parallel processing over the network by multiple computing nodes sharing the model training load. This setup is ideally suited for large data or complex models, as it facilitates faster processing and scalability.
For additional information on distribution training methodologies, such as data, tensor, and pipeline parallelism, see the previous blog post on inference parallelism and how it works.
Implementation mechanisms
Various tools and platforms are available to simplify infrastructure management when implementing model training architectures for AI/ML workloads, especially for distributed training patterns. These tools and mechanisms fall under two broad categories:
Container-orchestrated training: Containerization through technologies like Docker packages model training, and Kubernetes can deploy and scale ML training jobs, including distributed training patterns.
- Kubernetes for distributed training: Cloud providers such as EKS, GKE, and AKS provide managed Kubernetes services and simplify Kubernetes cluster management. Kubeflow with Kubernetes facilitates ML-specific capabilities.
- Elastic and scalable environment: Dynamic resource provisioning creates elastic, scalable environments.
Managed training services: Managed training services from cloud platforms such as AWS SageMaker, Google Vertex AI, and Azure ML provide predefined settings with optimized ML, including native support instances for distributed training patterns, storage, versioning, and data pipeline integration.
Model serving/inference architectures
Model serving or inference architectures are designed to deploy trained models to predict on real-time or batch data, converting models into practical solutions. These architectures differ from training architectures regarding latency, scalability, and efficiency.
Real-time inference patterns
Real-time inference patterns are used for critical applications that need real-time predictions once input is provided, like fraud detection, recommendation systems, or natural language processing. Models are served with REST or gRPC APIs to process synchronous requests and predictions with low latency, optimized by frameworks such as TensorFlow Serving, FastAPI, or SeldonCore. Moreover, autoscaling tools such as Kubernetes Horizontal Pod Autoscaler or cloud-native features dynamically adapt resource allocation, maintaining consistency as traffic rises.
Batch inference patterns
Batch inference patterns are used where predictions are generated for large volumes of data at regular intervals. It can be used for applications where real-time prediction is not required, like weekly fraud reports or daily sales reports.
Batch processing architectures gather and process large data sets with greater latency than real-time processing on platforms such as Apache Spark or Azure Data Factory. For automating this process, orchestration tools such as cron jobs or Apache Airflow are typically used to schedule and execute inference tasks.
Implementation mechanisms
Enterprises use model serving/inference architecture mechanisms using a diverse set of tools and platforms that handle a variety of use cases, improving flexibility, scalability, and performance.
Serverless inference
Serverless platforms such as AWS Lambda, Google Cloud Functions (GCFs), and Azure Functions allow performing computations without configuring or managing any underlying infrastructure. These platforms are useful for unpredictable inference workloads such as dynamic recommendation systems or IoT data processing.
Container-based serving
Containerized environments like Docker provide scalable, high-performance inference for large models by isolating dependencies and providing stable environments across multiple deployment stages. Such environments provide efficient serving with tools like TensorFlow Serving, designed specifically for TensorFlow models but compatible with other models as well, and NVIDIA Triton Inference Server, supporting several ML frameworks (TensorFlow, PyTorch, ONNX) with GPU acceleration. Also, KServe, a Kubernetes-native solution, supports scaling, monitoring, and model-wise intelligent routing, additionally enhancing deployment and flexibility.
Specialized inference services
Cloud-provider-based managed services such as AWS SageMaker Endpoints, Google Vertex AI Endpoints, and Azure ML Endpoints are optimized for deploying and scaling ML models at scale.
MLOps pipeline architectures
MLOps consists of a set of practices, tools, and technologies to automate and streamline the deployment, monitoring, and maintenance of ML models in production environments.
Using tools such as ClearML or KitOps, CI/CD for ML automates the processes of model development, testing, and deployment of ML models. Feature store integration, using tools like Feast or Tecton, centralizes the storage, management, and real-time sharing of features for models. A model registry, supported by open-source platforms such as MLFlow or DVC, helps monitor, manage, and version model artifacts, ensuring consistency and smooth deployment. Additionally, monitoring and observability tools like Prometheus, Grafana, AWS CloudWatch, and Azure Monitor track key metrics like accuracy and precision while also detecting issues like data drift or model degradation.
For a detailed description of MLOps components, refer to the MLOps for Beginners post. Here is an MLOps repository that contains a list of open source MLOps tools categorized for every step.
Implementation mechanisms
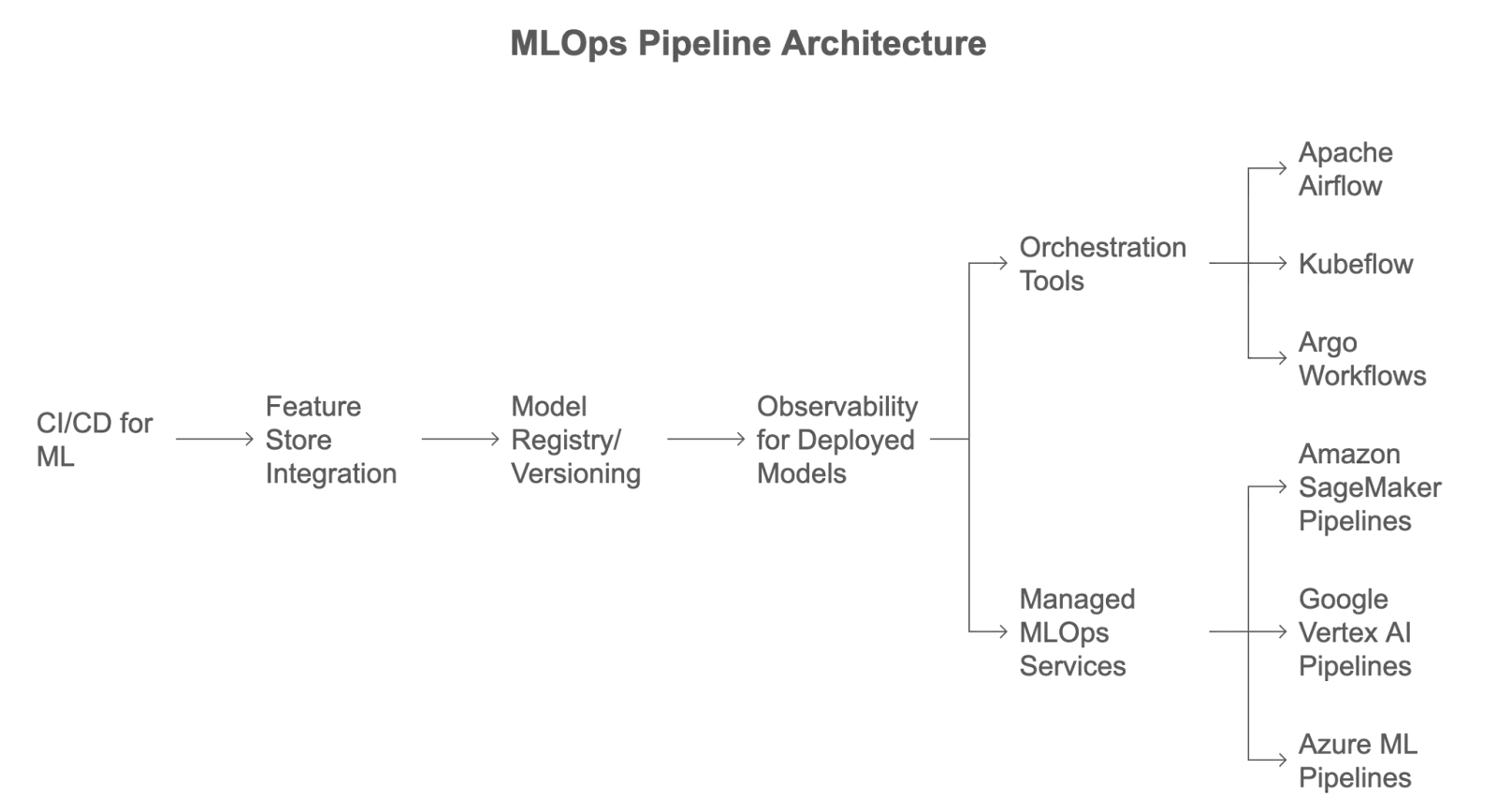
MLOps pipelines can be implemented using a variety of orchestration tools or managed services.
Orchestration tools: Orchestration tools allow flexibility and control to design and manage custom ML pipelines. Tools like Apache Airflow, which uses Directed Acyclic Graphs (DAGs) for ML workflow definition; Kubeflow, a Kubernetes-native platform with components like Kubeflow Pipeline for automating ML model lifecycle; and Argo Workflows, a container-native workflow engine for Kubernetes support to manage complex workflows.
Managed MLOps services: Some cloud providers offer MLOps integrated services like Amazon SageMaker Pipelines, which uses SageMaker Pipelines to manage and execute DAG-based workflows to streamline ML workflows. Google Vertex AI Pipelines, which is built on top of Kubeflow Pipelines for automating the orchestration of end-to-end ML workflows. Also, Azure ML Pipelines support the orchestration of ML workflows through a Python SDK or YAML configuration.
Key technical requirements across the ML lifecycle
A successful ML lifecycle enables ML models to be updated, scaled, and maintained effectively. MLOps includes a series of well-defined steps, each possessing its own technical requirements to meet accuracy, scalability, and maintainability throughout the ML model:
- Scalable infrastructure: On-premises or cloud-based computing resources, such as GPUs/TPUs or hybrid cloud platforms, are used for model training at a low cost and high performance.
- Automation and orchestration: CI/CD pipelines facilitate seamless transitions between experimentation, development, and production phases. Tools like Docker for containerization and Kubernetes for orchestration facilitate seamless deployments.
- Monitoring and observability: Real-time monitoring with tools such as Prometheus, Grafana, etc facilitates continuous monitoring of critical metrics such as model drift, latency, throughput, and accuracy, ensuring reliable model performance over time.
- Security and compliance: Maintaining data privacy, implementing robust access controls, and adhering to governance standards such as GDPR or HIPAA in compliance with regulatory requirements.
Refer to the introduction to MLOps blog post for an end-to-end overview of all the phases in the MLOps lifecycle.
Edge-cloud hybrid architectures
Edge-cloud hybrid models combine the capabilities of edge and cloud computing to provide low-latency and high-performance solutions while leveraging the scalability and flexibility of the cloud.
For example, in self-driving cars, real-time decision-making (e.g., detecting obstacles, managing navigation systems, applying braking, etc.) occurs at the edge (on the car itself) since latency for a few milliseconds can be mission-critical for safety. At the same time, large-scale data processing, model retraining, and fleet management occur in the cloud, where computational resources are virtually unlimited. With this hybrid architecture, these cars can achieve real-time responsiveness for immediate actions while leveraging the cloud’s scalability for long-term data processing and model improvements.
Edge deployment patterns
Edge deployment patterns refer to deploying and running ML models or applications directly on edge devices (e.g., IoT devices, gateways, or edge servers) to process data locally, reducing latency and improving responsiveness. These patterns include on-device inference, edge gateway inference, or federated learning.
Edge-cloud coordination
This hybrid architecture ensures that edge and cloud components communicate seamlessly while maintaining consistency, synchronization, and efficiency throughout the architecture. Data synchronization, data offloading, load balancing, and resource sharing are some of the most important aspects of this architecture.
Model optimization for edge
Model optimization methods like model quantization, model pruning, edge-specific frameworks, and hardware acceleration are used to reduce the complexity and size of models to make them fit to run on resource-constrained edge devices.
Implementation approaches
By combining edge containers, orchestration tools, and a cloud synchronization mechanism, the hybrid architecture can also have several implementation strategies that efficiently handle both architectures.
Edge containers and orchestration
Containers (e.g., Docker) are used to package ML models into lightweight, portable units. Kubernetes and edge-specific orchestration solutions, such as KubeEdge or EdgeX Foundry, are used to manage and scale these containers across distributed edge environments. These tools enable scalable, consistent, and efficient application deployment on distributed edge devices.
Cloud synchronization mechanisms
Cloud synchronization techniques enable the seamless transfer of data and models between edge and cloud environments using message queues (e.g., AWS IoT Core, Azure IoT Hub) for asynchronous communication, data replication methods like Change Data Capture (CDC) for near real time or real-time updates, and model synchronization tools such as MLflow, SageMaker Edge Manager, or LiteRT to manage model updates across distributed devices.
Architectural decision framework
Since we have discussed many architectural patterns, such as edge-cloud hybrid models and edge deployment patterns, it is important to understand and determine which architecture best meets the particular requirements. Decisions on the right ones are based on a number of factors, including workload patterns, cost considerations, security, compliance, and cloud provider capabilities.
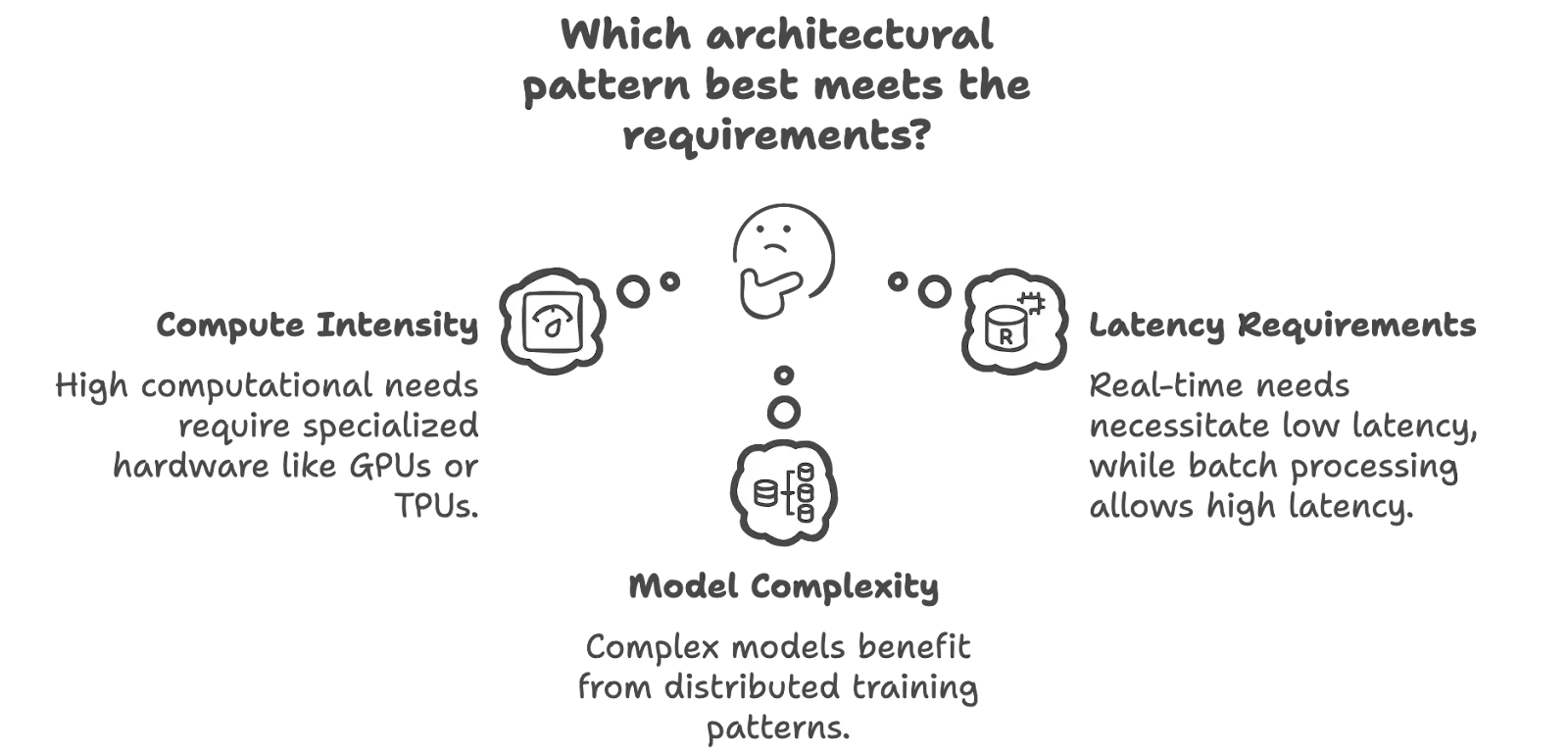
Decision criteria based on workload characteristics
Each workload has characteristics, such as performance, scalability, latency, and complexity, that influence architectural decisions. Evaluating these ensures technically viable designs aligned with business needs. The following characteristics can help choose the architecture:
- Compute intensity: AI/ML training workloads require significant computational power and specialized hardware, such as NVIDIA GPUs or Google TPUs, for efficient processing.
- Latency requirements: Some workloads, such as fraud detection and autonomous inference, need low latency, but model retraining relies on high-latency batch processing for accuracy.
- Model complexity: Model complexity affects training choices—simple models are suitable for single nodes, whereas complicated models may require distributed training (e.g., TensorFlow Distributed Training) to meet computation and memory demands.
Cost optimization strategies
Cost optimization is one of the critical considerations when scaling AI/ML systems, where architectural choices can be optimized while choosing cost-efficient strategies. A few strategies include:
- Resource rightsizing: Align resource allocation with workload needs using tools like AWS Compute Optimizer, Azure Advisor, or Google Cloud Recommendations to avoid overprovisioning and cut costs.
- Spot and reserved instances: AWS Spot instances can be leveraged for non-critical workloads to reduce costs, and AWS reserved instances can be used for predictable workloads to reserve lower rates for a specific term.
- Serverless architectures: Serverless environments, such as AWS Lambda or GCFs, are ideal for event-driven workloads because they automatically scale with demand and reduce idle resource expenses.
- Model quantization: Model size can be minimized by mapping weights from high-precision (e.g., 32-bit floats) to lower precision formats (e.g., 16-bit, 8-bit, or 4-bit), lowering compute costs.
- Model distillation: Use smaller student models to imitate bigger teacher models for inference, reducing time and cost while retaining acceptable accuracy.
Security and compliance considerations
Security and compliance are critical factors for protecting data and infrastructure in AI/ML architectures. A few common considerations are:
- Data encryption: Using cloud provider encryption services such as AWS Key Management Service (KMS), Azure Key Vault, or Google KMS, data can be encrypted at rest or using TLS/SSL in transit to avoid any data breaches.
- Access control: Implement role-based access control policies with fine-grained permissions using AWS Identity Access Management (IAM), Google Cloud IAM, or Azure RBAC.
- Backup and disaster recovery: Use cloud-native tools like AWS Backup, Azure Backup, or Google Cloud Backup and DR to back up model artifacts, training data, or inference endpoints. Based on data volume and compliance needs, choose suitable Recovery Point Objectives (RPOs) and Recovery Time Objectives (RTOs).
Cloud provider selection factors
Every cloud provider offers different levels of support, pricing, AI services, and infrastructure, and choosing the appropriate one among them requires various key factors to be taken into consideration, such as:
- Service offerings: Assess the wide variety of AI/ML services provided by the cloud providers like AWS SageMaker, Azure ML, and Google Vertex AI for managed workflows, inference, and MLOps tools.
- Pricing models: Compare cloud providers’ computing, storage, and AI pricing strategies, including pay-as-you-go, reserved instances, spot pricing, or commitment-based options.
- Geographical presence: Consider the cloud provider’s availability zones and data center regions, and confirm that the data center locations meet the regional requirements for latency, availability, and compliance needs.
- Integration capabilities: Evaluate the cloud providers that offer seamless integrations with ML frameworks (e.g., TensorFlow, PyTorch), orchestration tools (e.g., Kubernetes, Apache Airflow), and data platforms (such as Snowflake or Databricks).
Note: When choosing a cloud service, keep vendor lock-in in mind, as this can limit future flexibility and raise long-term expenses.
Future trends
As AI technology is dynamically evolving and transforming, enterprises are increasingly shifting towards adopting AI/ML technologies to maximize their operations and drive innovations. Thus, the architectural requirements to deploy and scale AI workloads within cloud infrastructures are significantly transforming. Here are the three important trends that will mold the landscape of AI cloud architectures in the future:
Multi-cloud AI architectures
With the rise of multi-cloud architecture, enterprises use multi-cloud providers to develop, train, and deploy AI/ML models instead of conventional cloud deployments to host their workloads. The key reasons include:
- High availability: Redundancy across multiple clouds reduces the risk of downtime.
- Optimized latency: Placement of workloads across different clouds reduces latency.
- Unified MLOps: Tools like Kubernetes, Kubeflow, Terraform, and cross-cloud orchestration facilitate the management and deployment of AI workloads.
Emerging specialized AI infrastructure
Demand for advanced and specialized infrastructure for managing AI/ML workloads is driving cloud providers to develop highly specialized hardware to expedite AI/ML workload training and inference, resulting in significant performance improvements over typical hardware. Below are a few emerging AI infrastructures:
- GPUs and TPUs: Next-gen tools such as NVIDIA Hopper
- AI-specific chips: AI-accelerated chips like NVIDIA A100 or Google’s TPUs
- Quantum computing: Revolutionize AI model training for solving complex optimization
AI-specific networking advances
Networking infrastructure is evolving to support the increasing complexity of AI/ML workloads and to complement existing networking technologies, which are often insufficient to satisfy the demands of advanced AI workloads, particularly in areas such as low latency and high throughput.
- Technologies such as InfiniBand and Remote Direct Memory Access (RDMA) provide low latency and high throughput between nodes.
- SDN facilitates dynamic network configuration to address the needs of AI workloads.
- Network Function Virtualization (NFV) enables network service virtualization, enabling flexible deployment of AI workloads.
Conclusion
AI cloud architecture patterns are continuously evolving and efficiently meeting the demands of complex AI/ML workloads. By understanding the different workload patterns, implementation mechanisms, workload requirements, architectural decision framework, and emerging trends, enterprises can develop robust, scalable, flexible, and resilient AI architectures that efficiently manage their varying workloads.
Harnessing the right combination of cloud provider-hosted managed services and container orchestration technologies can make the task of creating and tuning AI infrastructure a whole lot easier.
Whether you’re starting out with AI cloud architecture or seeking to streamline your current deployments, adopting new cloud technologies and best practices can help you remain competitive in the fast-changing world of AI. From distributed training and real-time inference to multi-cloud strategies and optimized AI hardware, the correct architectural choices can unlock new levels of performance and efficiency.
Are you ready to take the next step in AI cloud architecture innovation? If you’re looking for experts who can help you scale or build your AI infrastructure, reach out to our AI & GPU Cloud experts.
If you found this post valuable and informative, subscribe to our weekly newsletter for more posts like it. I’d love to hear your thoughts on this post, so do start a conversation on LinkedIn.
Stay updated with latest in AI and Cloud Native tech
We hate 😖 spam as much as you do! You're in a safe company.
Only delivering solid AI & cloud native content.
Posts You Might Like